Context Engineering in Manus
Why Context Engineering
Earlier this week, I had a webinar with Manus co-founder and CSO Yichao “Peak” Ji. You can see the video here, my slides here, and Peak’s slides here. Below are my notes.
Anthropic defines agents as systems where LLMs direct their own processes and tool usage, maintaining control over how they accomplish tasks. In short, it’s an LLM calling tools in a loop.
Manus is one of the most popular general-purpose consumer agents. The typical Manus task uses 50 tool calls. Without context engineering, these tool call results would accumulate in the LLM context window. As the context window fills, many have observed that LLM performance degrades.
For example, Chroma has a great study on context rot and Anthropic has explained how growing context depletes an LLM’s attention budget. So, it’s important to carefully manage what goes into the LLM’s context window when building agents. Karpathy laid this out clearly:
Context engineering is the delicate art and science of filling the context window with just the right information for the next step (in an agent’s trajectory)
Context Engineering Approaches
Each Manus session uses a dedicated cloud-based virtual machine, giving the agent a virtual computer with a filesystem, tools to navigate it, and the ability to execute commands (e.g., provided utilities and standard shell commands) in that sandbox environment.
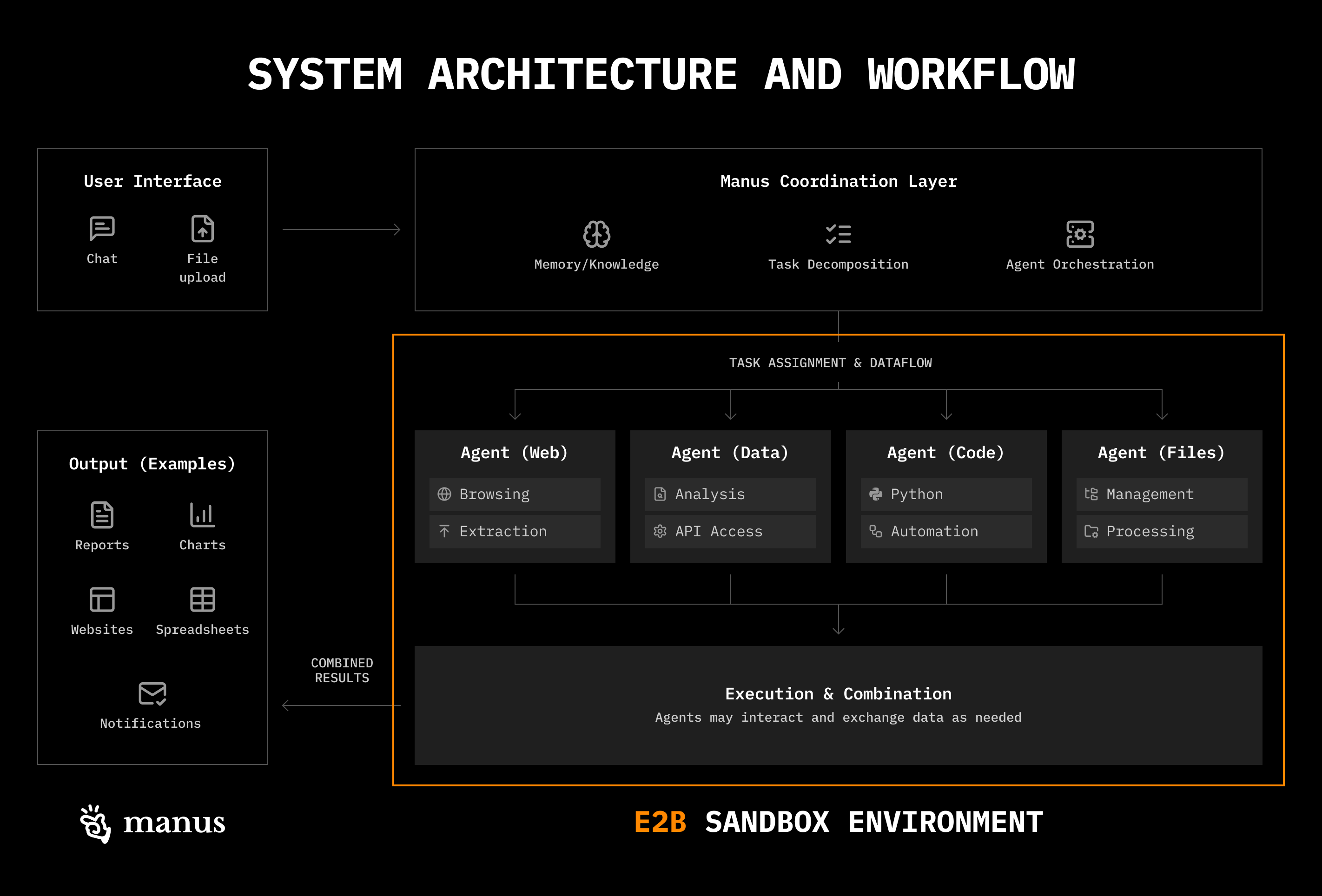
In this sandbox, Manus uses three primary strategies for context engineering, which align with approaches Anthropic covers here and I’ve seen in across many projects:
- Reduce Context
- Offload Context
- Isolate Context
Context Reduction
Tool calls in Manus have a “full” and “compact” representation. The full version contains the raw content from tool invocation (e.g., a complete search tool result), which is stored in the sandbox (e.g., filesystem). The compact version stores a reference to the full result (e.g., a file path).
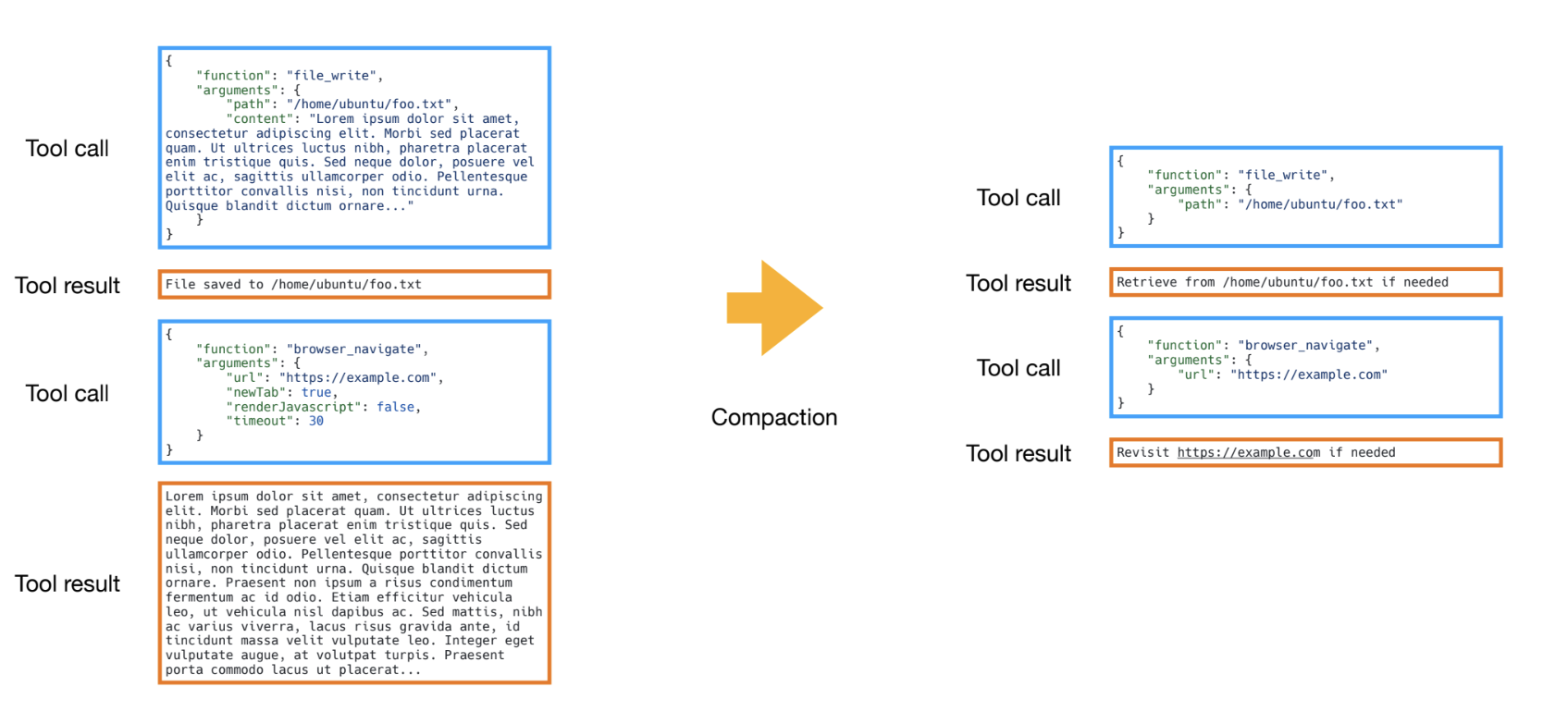
Manus applies compaction to older (“stale”) tool results. This just means swapping out the full tool result for the compact version. This allows the agent to still fetch the full result if ever needed, but saves tokens by removing “stale” results that the agent has already used to make decisions.
Newer tool results remain in full to guide the agent’s next decision. This seems to be a generally useful strategy for context reduction, and I notice that it’s similar to Anthropic’s context editing feature:
Context editing automatically clears stale tool calls and results from within the context window when approaching token limits. As your agent executes tasks and accumulates tool results, context editing removes stale content while preserving the conversation flow, effectively extending how long agents can run without manual intervention.
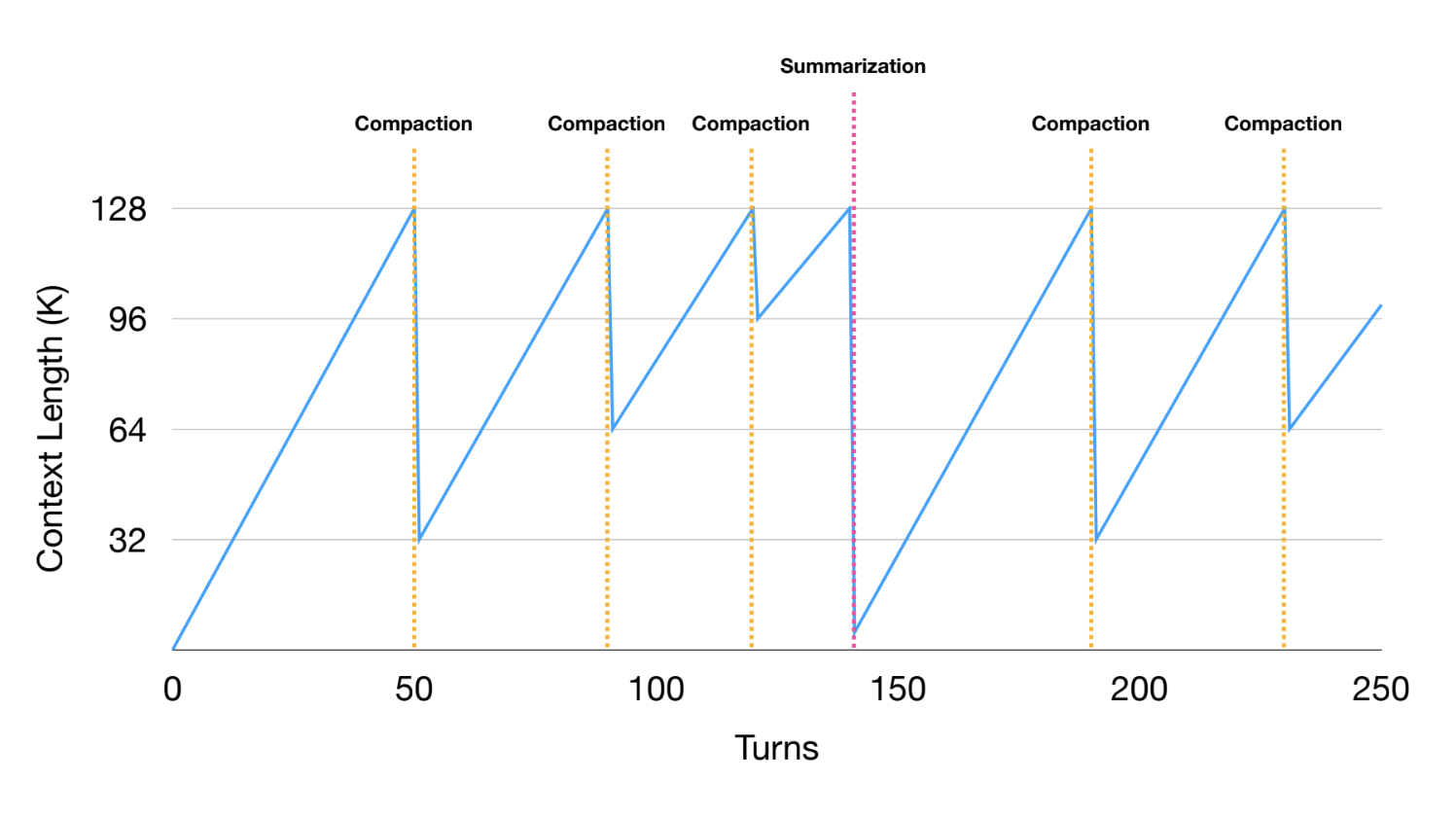
When compaction reaches diminishing returns (see figure below), Manus applies summarization to the trajectory. Summaries are generated using full tool results and Manus uses a schema to define the summary fields. This creates a consistent summary object for any agent trajectory.
Context Isolation
Manus takes a pragmatic approach to multi-agent, avoiding anthropomorphized divisions of labor. While humans organize by role (designer, engineer, project manager) due to cognitive limitations, LLMs don’t necessarily share these same constraints.
With this in mind, the primary goal of sub-agents in Manus is to isolate context. For example, if there’s a task to be done, Manus will assign that task to a sub-agent with its own context window.
Manus uses multi-agent with a planner that assigns tasks, a knowledge manager that reviews conversations and determines what should be saved in the filesystem, and an executor sub-agent that performs tasks assigned by the planner.
Manus initially used a todo.md for task planning, but found that roughly one-third of all actions were spent updating the todo list, wasting valuable tokens. They shifted to a dedicated planner agent that calls executor sub-agents to perform tasks.
In a recent podcast, Erik Schluntz (multi-agent research at Anthropic) mentioned that they similarly design multi-agent systems with a planner to assign tasks and use function calling as the communication protocol to initiate sub-agents. A central challenge raised by Erik as well as Walden Yan (Cognition) is context sharing between planner and sub-agents.
Manus addresses this in two ways. For simple tasks (e.g., a discrete task where the planner only needs the output of the sub-agent), the planner simply creates instructions and passes them to the sub-agent via the function call. This resembles Claude Code’s task tool.
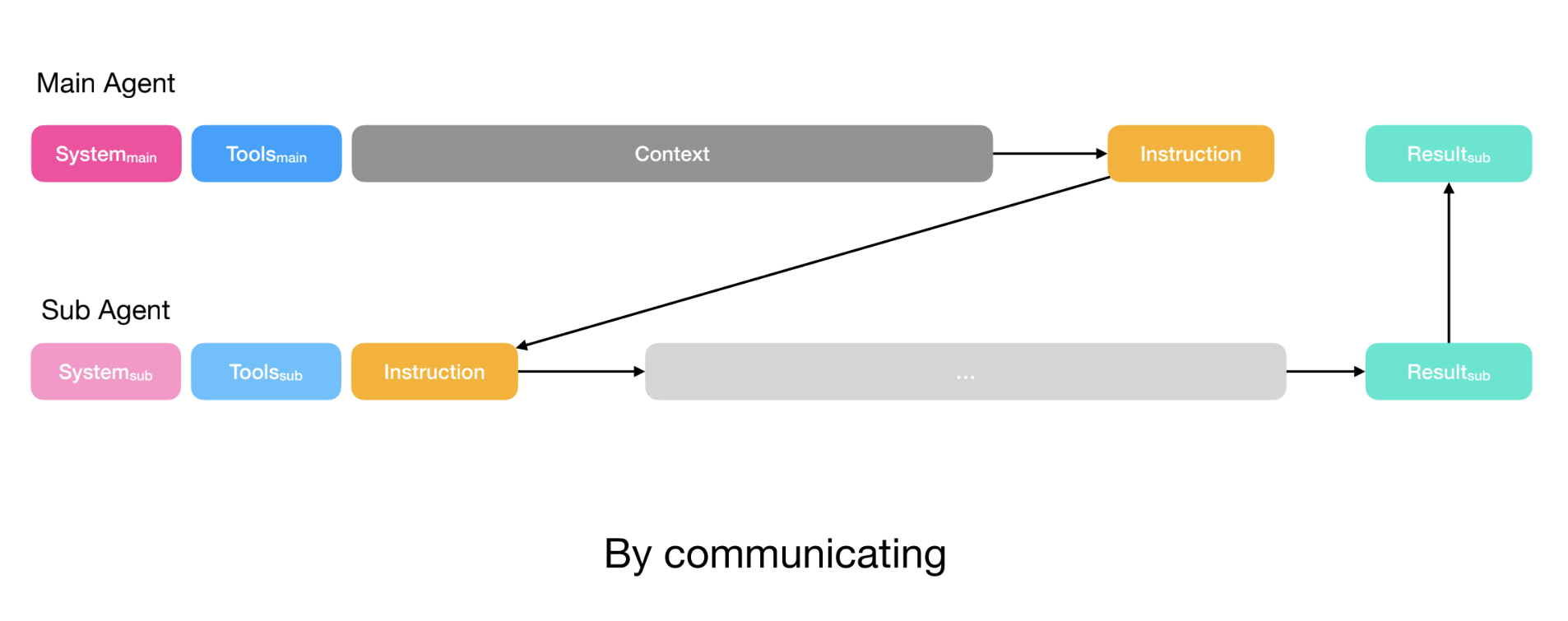
For more complex tasks (e.g., the sub-agent needs to write to files that the planner also uses), the planner shares its full context with the sub-agent. The sub-agent still has its own action space (tools) and instructions, but receives the full context that the planner also has access to.
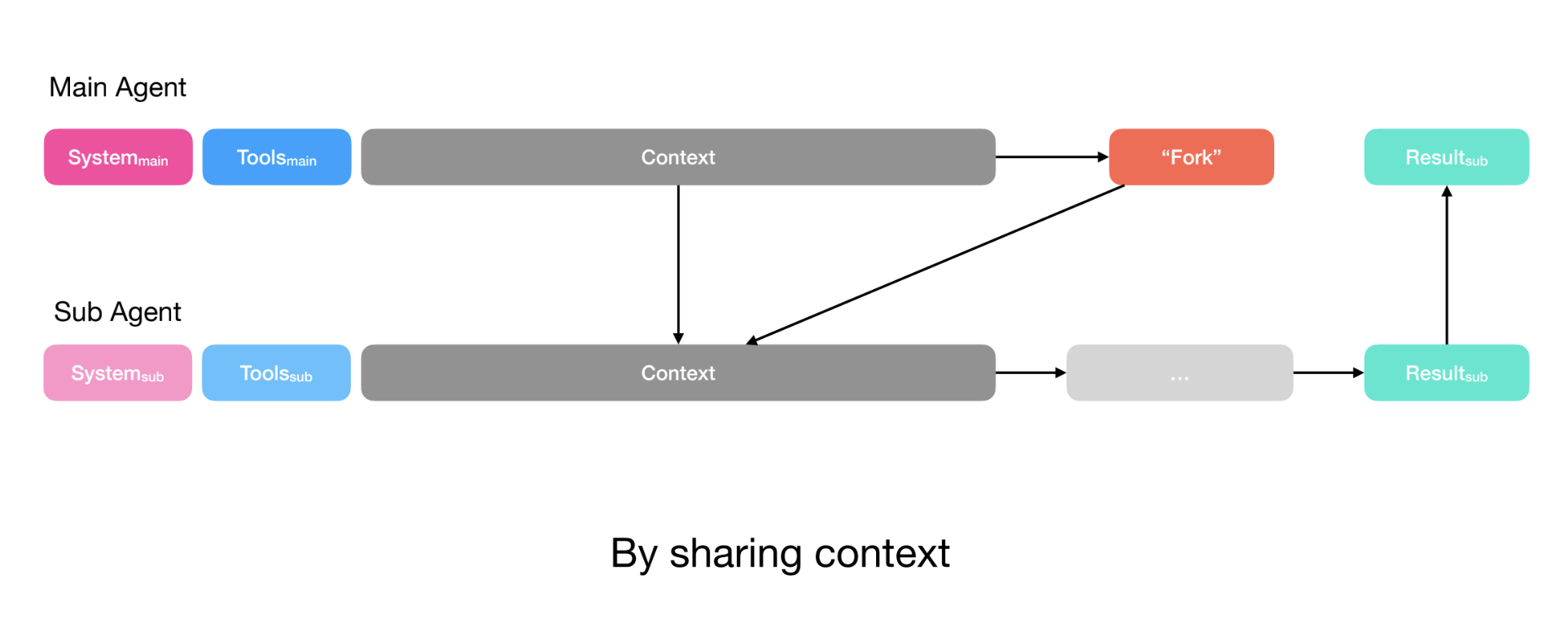
In both cases, the planner defines the sub-agent’s output schema. Sub-agents have a submit results tool to populate this schema before returning results to the planner and Manus uses constrained decoding to ensure output adheres to the defined schema.
Context Offloading
Tools Definitions
We often want agents that can perform a wide range of actions. We can, of course, bind a large collection of tools to the LLM and provide detailed instructions on how to use all of them. But, tool descriptions use valuable tokens and many (often overlapping or ambiguous) tools can cause model confusion.
A trend I’m seeing is that agents use a small set of general tools that give the agent access to a computer. For example, with only a Bash tool and a few tools to access a filesystem, an agent can perform a wide range of actions!
Manus thinks about this as a layered action space with function/tool calling and its virtual computer sandbox. Peak mentioned that Manus uses a small set (< 20) of atomic functions; this includes things like a Bash tool, tools to manage the filesystem, and a code execution tool.
Rather than bloating the function calling layer, Manus offloads most actions to the sandbox layer. Manus can execute many utilities directly in the sandbox with its Bash tool and MCP tools are exposed through a CLI that the agent can also execute using the Bash tool.
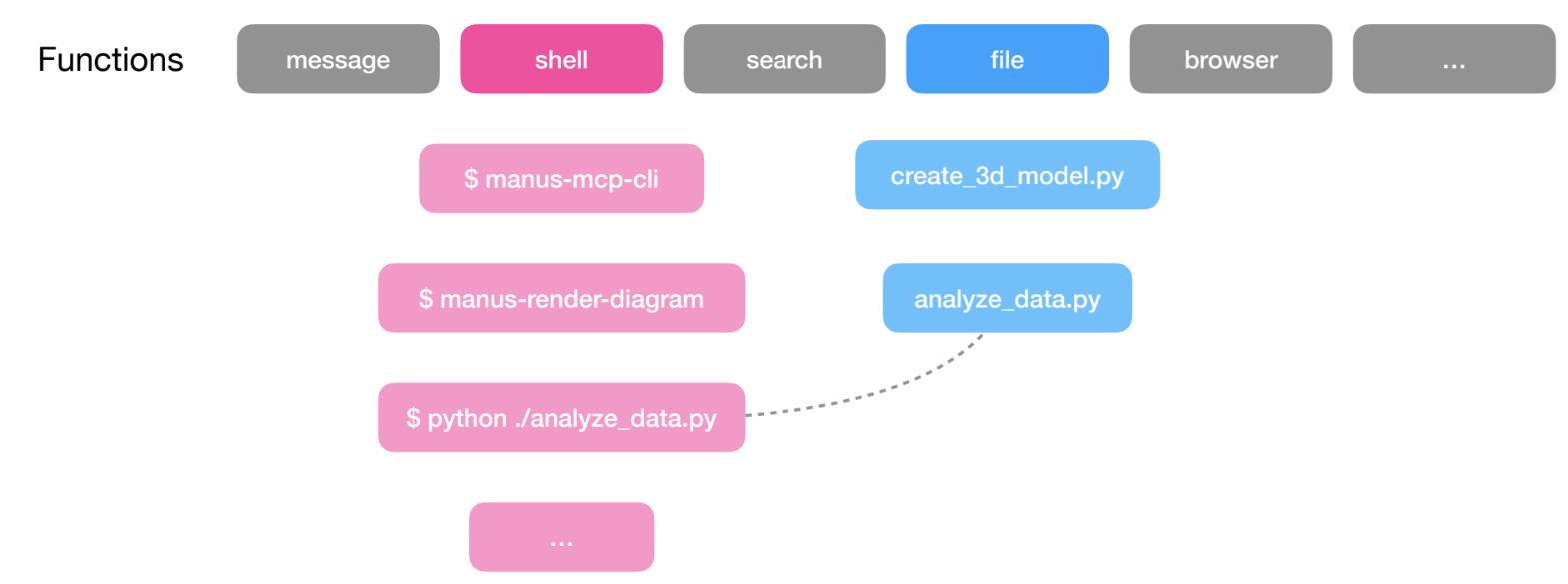
Claude’s skills feature uses a similar idea: skills are stored in the filesystem, not as bound tools, and Claude only needs a few simple function calls (Bash, file system) to progressively discover and use them.
Progressive disclosure is the core design principle that makes Agent Skills flexible and scalable. Like a well-organized manual that starts with a table of contents, then specific chapters, and finally a detailed appendix, skills let Claude load information only as needed … agents with a filesystem and code execution tools don’t need to read the entirety of a skill into their context window when working on a particular task.
Tool Results
Because Manus has access to a filesystem, it can also offload context (e.g., tool results). As explained above, this is central for context reduction; tool results are offloaded to the filesystem in order to produce the compact version and this is used to prune stale tokens from the agent’s context window. Similar to Claude Code, Manus uses basic utilities (e.g., glob and grep) to search the filesystem without the need for indexing (e.g., vectorstores).
Model Choice
Rather than committing to a single model, Manus uses task-level routing: it might use Claude for coding, Gemini for multi-modal tasks, or OpenAI for math and reasoning. Broadly, Manus’s approach to model selection is driven by cost considerations, with KV cache efficiency playing a central role.
Manus uses caching (e.g., for system instructions, older tool results, etc) to reduce both cost and latency across many agent turns. Peak mentioned that distributed KV cache infrastructure is challenging to implement with open source models, but is well-supported by frontier providers. This caching support can make frontier models cheaper for certain (agent) use-cases in practice.
Build with the Bitter Lesson in Mind
We closed the discussion talking about the Bitter Lesson. I’ve been interested in its implications for AI engineering. Boris Cherny (creator of Claude Code) mentioned that The Bitter Lesson influenced his decision to keep Claude Code unopinionated, making it easier to adapt to model improvements.
Building on constantly improving models means accepting constant change. Peak mentioned that Manus has been refactored five times since their launch in March!
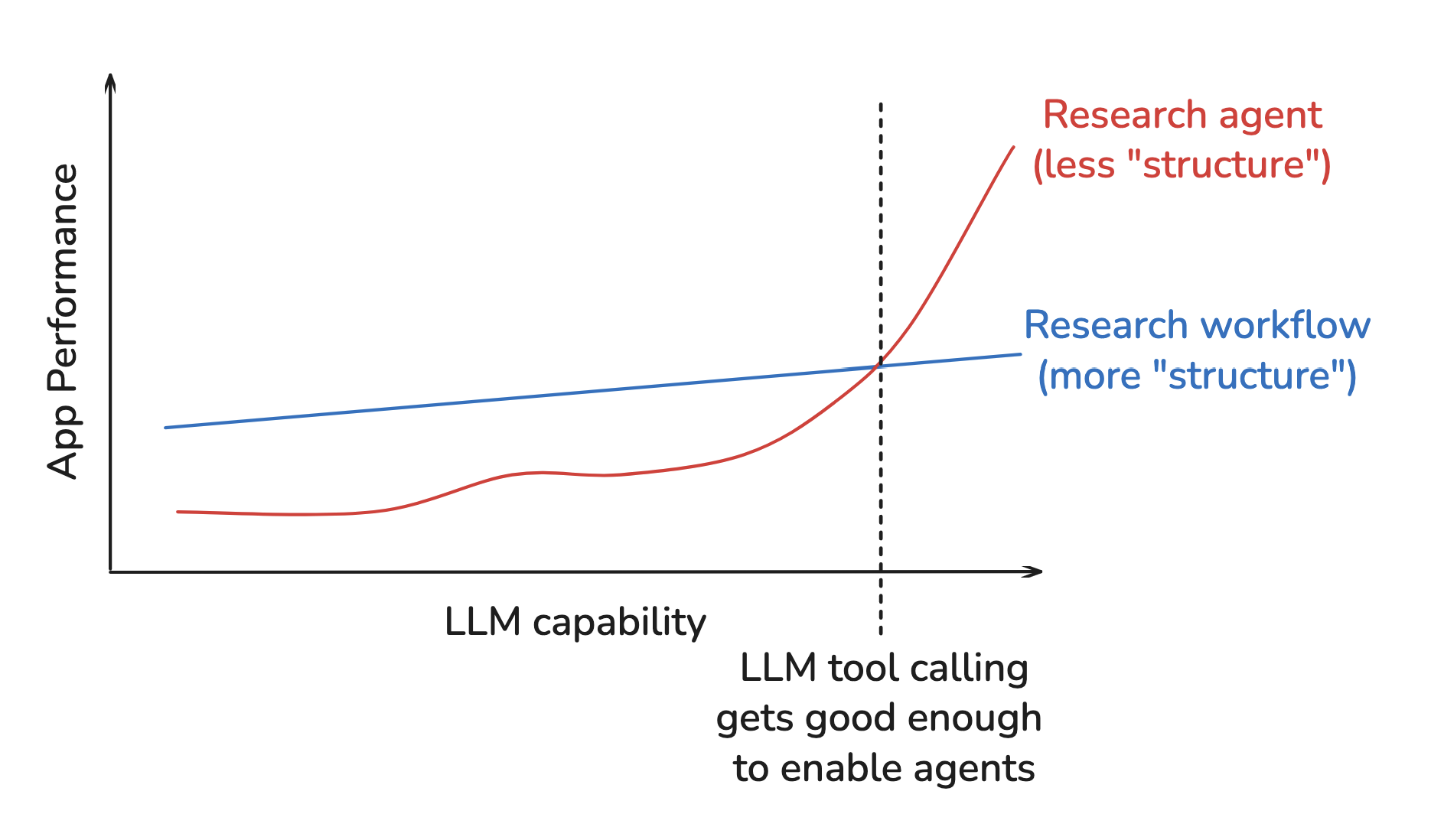
In addition, Peak warned that the agent’s harness can limit performance as models advance; this is exactly the challenge called out by the Bitter Lesson. We add structure to improve performance at a point in time, but this structure can limit performance as compute (models) grows.
To guard against this, Peak suggested running agent evaluations across varying model strengths. If performance doesn’t improve with stronger models, your harness may be hobbling the agent. This can help test whether your harness is “future proof”.
Hyung Won Chung’s (OpenAI/MSL) talk on this topic further emphasizes the need to consistently re-evaluate structure (e.g., your harness / assumptions) as models improve.
Add structures needed for the given level of compute and data available. Remove them later, because these shortcuts will bottleneck further improvement.
Conclusions
Giving agents access to a computer (e.g., filesystem, terminal, utilities) is a common pattern we see across many agents, including Manus. It enables a few context engineering strategies:
1. Offload Context
- Store tool results externally: Save full tool results to the filesystem (not in context) and access on demand with utilities like
globandgrep - Push actions to the sandbox: Use a small set of function calls (Bash, filesystem access) that can execute many utilities in the sandbox rather than binding every utility as a tool
2. Reduce Context
- Compact stale results: Replace older tool results with references (e.g., file paths) as context fills; keep recent results in full to guide the next decision
- Summarize when needed: Once compaction reaches diminishing returns, apply schema-based summarization to the full trajectory
3. Isolate Context
- Use sub-agents for discrete tasks: Assign tasks to sub-agents with their own context windows, primarily to isolate context (not to divide labor by role)
- Share context deliberately: Pass only instructions for simple tasks; pass full context (e.g., trajectory and shared filesystem) for complex tasks where sub-agents need more context
A final consideration is to ensure your harness is not limiting performance as models improve (e.g., be “Bitter Lesson-pilled”). Test across model strengths to verify this. Simple, unopinionated designs often adapt better to model improvements. Finally, don’t be afraid to re-build your agent as models improve (Manus refactored 5 times since March)!