Vibe code benchmark
Summary
I compared Cursor and Claude Code on a set of coding challenges, giving them access to external documentation in 4 different ways: an llm.txt file (with and without optimized descriptions), a vector database, and direct context stuffing. A well-crafted (optimized) llms.txt file paired with Claude Code outperformed all other approaches. llms.txt leverages reasoning the in the retrieval step, allowing the LLM to pick and choose specific documents to retrieve.
Challenge
Code agents like Cursor and Claude Code are transforming software development. Protocols like MCP (Model Context Protocol) connect these agents with external data sources. I was curious about the performance of different code agents and the various ways to connect them with data.
I selected 5 code questions (see prompts here) that require LangGraph documentation (~260k tokens). For each question, I prompted Claude Code and Cursor and allowed them to complete the task autonomously (by accepting all tool calls / diffs aka “vibe coding”). I gave them access to LangGraph documentation in different ways:
-
Context Stuffing: I gave all LangGraph docs (~260k tokens) to the code agent.
-
Standard llms.txt:
llms.txtfiles provide background information, links, and page descriptions to LLMs. I gave the code agent an MCP server with access to the LangGraphllms.txtfile and a URL loader tool. -
Optimized llms.txt: I used an LLM to re-write the LangGraph
llms.txtfile with clearer, more consistent URL descriptions and gave this to the code agent via an MCP server. -
Vector Database: I built a vector database of the LangGraph documentation (8k token chunks, k=3, OpenAI
text-embedding-3-large) and gave it to the code agent via an MCP server for semantic search.
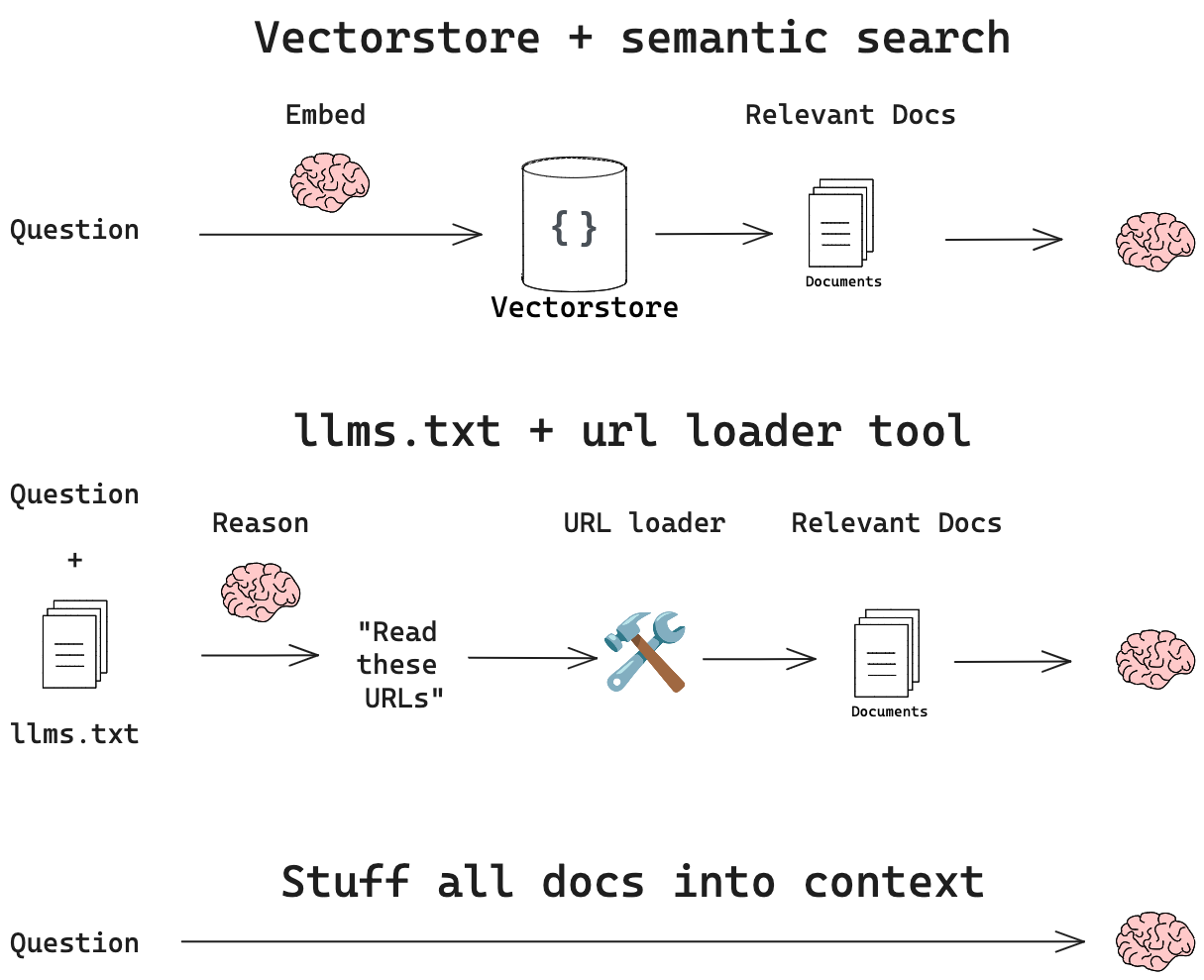
Evaluation
Each of the 5 code question prompts instructed the agent to generate a script, which I evaluated:
- Import Success (0-1 points): Can the code be imported without errors?
- Run Success (0-1 points): Does the script run without error?
- LLM Quality Score (0-1 points): Does the output meets the challenge requirements?
- Deployment Score (0-0.5 points): Can the code be deployed?
Each script could earn up to 3.5 points, with a maximum of 17.5 points possible per experiment (5 challenges × 3.5 points). I ran each experiment on separate branches to prevent cross-contamination, with all generated code stored in the experiments folders here, evaluation code here, results here.
Results
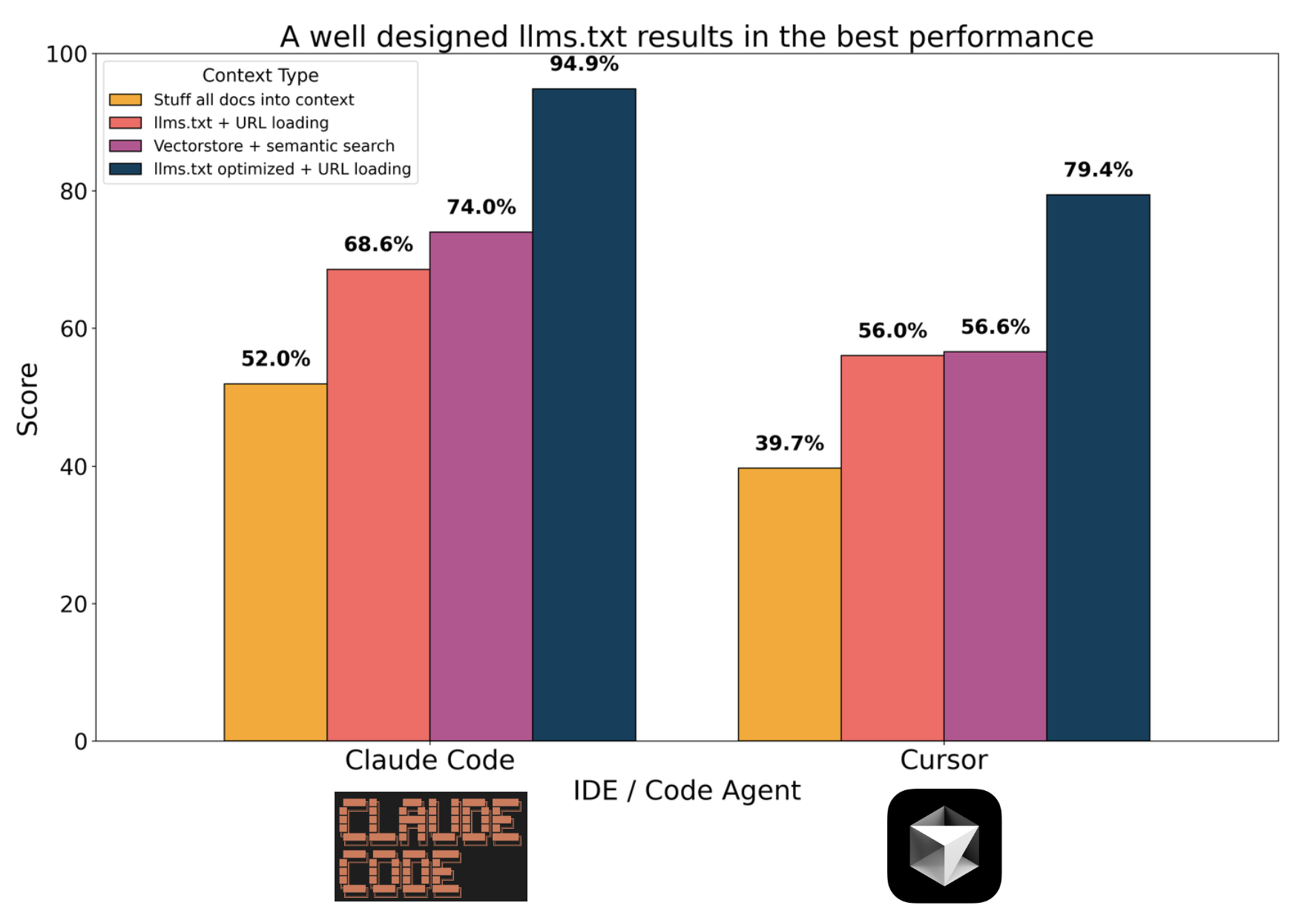
There is a consistent pattern: optimized llms.txt > vector database > llms.txt > context stuffing. llms.txt is just RAG with full documents as retrieval units. The LLM reasons directly about the URL descriptions in llms.txt and decides which documents to retrieve with a URL loader tool.
It’s a simple, but relies on good document descriptions: I noticed that the descriptions were pretty bad in the initial llms.txt file. So, I had an LLM read each URL and summarize it (here’s a package I made for this), creating the optimized llms.txt. This performed better on the benchmark.
Vector databases scale well, but retrieval can be sensitive to things like embedding, chunk size, k-nearest neighbors, etc. This makes them a bit tricky to get right, and it’s possible I didn’t tune it as well as I could have (e.g., maybe my chunk size or k - number of documents retrieved - were too small).
Context stuffing is the simplest approach, but shows the most errors. The fairly large context (266k tokens) may present surface area for the LLM to mix up concepts from different parts of the documentation. Error analysis of the log shows that most errors (6/11) are related to importing non-existent modules or functions (hallucinated APIs), and 3 / 5 of the errors with llmsfull are caused by this.
| Context Type | Import Errors | Graph Config Errors | Type Errors | API/Service Errors | Total Errors |
|---|---|---|---|---|---|
| llmsfull | 3 | 1 | 1 | 0 | 5 |
| llmstxt | 2 | 1 | 0 | 0 | 3 |
| llmstxt_updated | 0 | 0 | 1 | 0 | 1 |
| vectorstore | 1 | 0 | 0 | 1 | 2 |
| Total | 6 | 2 | 2 | 1 | 11 |
Overall, the strongest result was from Claude Code with the optimized llms.txt file. With this approach, all scripts had a passing Deployment Score by correctly formatting the langgraph.json file. This required understanding the LangGraph server application structure from one of the docs while also understanding other documents related to each specific challenge. llms.txt gives the LLM clear ability to pick and choose specific documents to retrieve to solve.
Conclusion
How we connect context to code agents impacts their performance. The optimized llms.txt approach with Claude Code achieved the best overall results and offers a nice approach that’s fairly easy to understand and implement with an MCP server server that has a URL loader tool.
Notes and Acknowledgements
Thanks to @veryboldbagel for the helpful feedback, discussion, and work on the MCP server / llms.txt files. The experiments ran with Claude Code (claude-3-7-sonnet-20250219) and Cursor version 0.47.8(claude-3-7-sonnet in thinking mode).
Notes [4/6/25]
I added an analysis of “context stuffing” llms-full.txt with Gemini 2.5 Pro in Cursor and llama4-maverick with 1M and 10M token context windows, respectively. Gemini 2.5 Pro appears to be very strong with direct retrieval from long context windows, and I’ll need to look into this further with additional testing.
| Model | Score |
|---|---|
| Llama-4-Maverick | 40% |
| Gemini 2.5 Pro | 85% |